There are a lot of bad takes out there so it’s probably worth collecting some good ones.
DeepSeek-V3 was released 2024-12-26: https://api-docs.deepseek.com/news/news1226 DeepSeek-R1 was released 2025-01-20: https://api-docs.deepseek.com/news/news250120
NOTE: US President Donald Trump proposed up to 100% tariffs on Taiwanese imports (eg, all advanced semi-conductors) on Monday 1/27 and the entire tech-sector market drop that was being attributed to DeepSeek news was most likely insider-trading of this announcement:
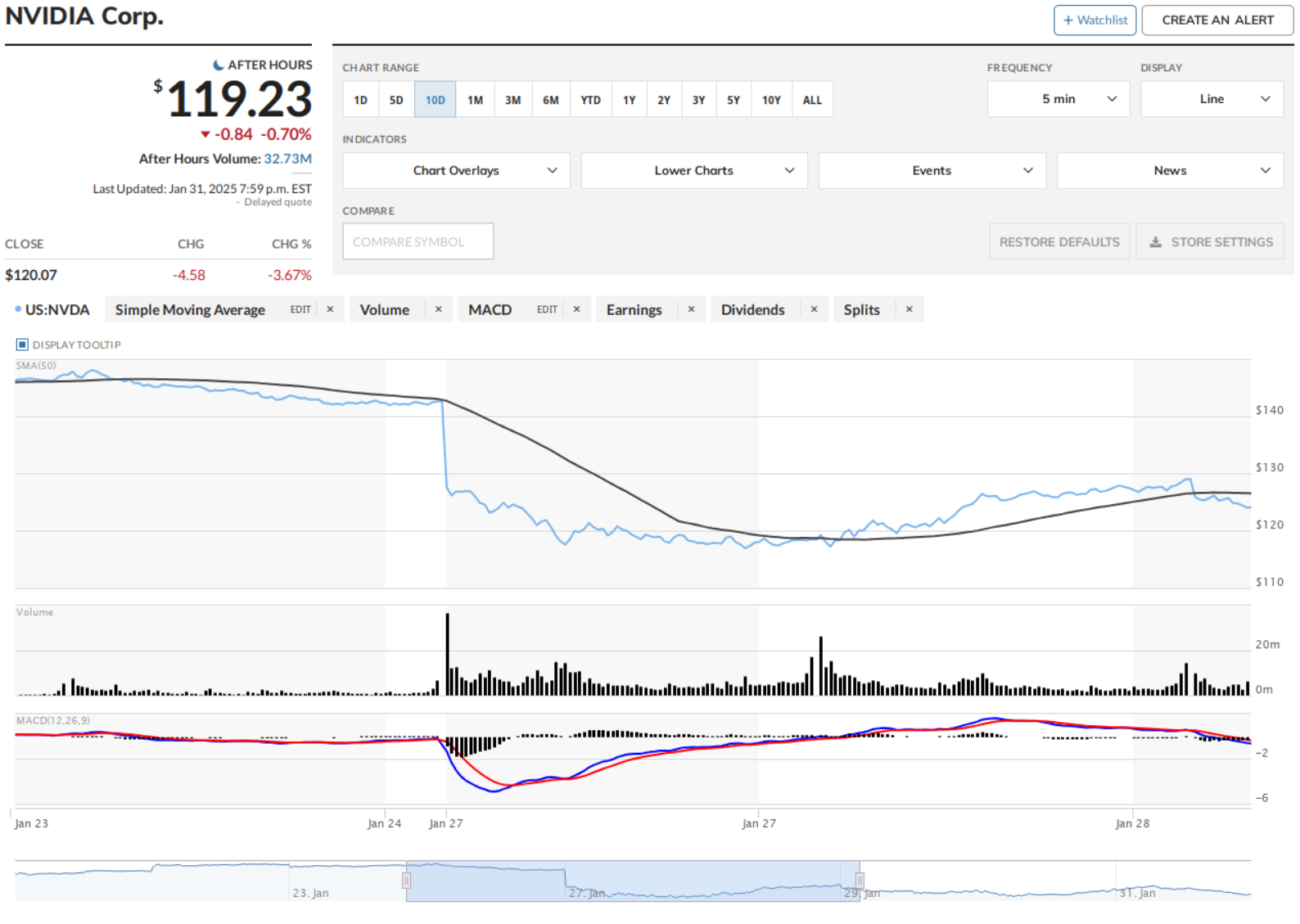
I would strongly under-index any analysis that failed to take this into account. It’s worth noting that from a logical perspective, DeepSeek’s success should help drive additional GPU demand:
- Stronger open source models drive more demand for on-prem inference, not less: https://www.reddit.com/r/LocalLLaMA/comments/1iehstw/gpu_pricing_is_spiking_as_people_rush_to_selfhost/
- A lot of garbo-takes on how “R1” can be run on a potato, but quants of the “distill” models are not R1, and the full R1 FP8 model requires either an MI300X, H200 node, or 2xH100 nodes (1 node = 8 GPUs). That’s at least $250-500K for just the systems alone
Technical
If you are trying to understand the latest DeepSeek models it’s probably best to start with the first-party papers, they are well written and relatively in-depth:
- 2025-01-22 DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- 2024-12-27 DeepSeek-V3 Technical Report
- 2024-05-07 DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
- 2024-01-05 DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
They have of course, published more:
- https://arxiv.org/search/cs?searchtype=author&query=DeepSeek-AI
- https://arxiv.org/search/?query=DeepSeek&searchtype=title&abstracts=show&order=-announced_date_first&size=50
- https://arxiv.org/search/cs?query=Guo%2C+Daya&searchtype=author&abstracts=show&order=-announced_date_first&size=50
For those looking for more on the DeepSeek infrastructure optimization, there is one paper on optimizing a 10,000 A100 GPU cluster that is not commonly cited:
- 2024-08-26 Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication.
There’s been a lot of misunderstanding of how much training frontier base-models cost. For some good analysis on this, see:
- 2025-01-10 DeepSeek V3 and the actual cost of training frontier AI models
- By Nathan Lambert, the post-training lead at the Allen Institute for AI who train the OLMo open models and Tülu open post-train recipe models
- 2025-01-31 DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts
- SemiAnalysis has been doing some of the best independent on datacenter compute hardware/infrastructure for years now. They recently done deep analysis on AI export controls and on the state of MI300X LLM training as good examples of their different types of work.
Analysis
2024-11-27 Deepseek: The Quiet Giant Leading China’s AI Race https://www.chinatalk.media/p/deepseek-ceo-interview-with-chinas
In the face of disruptive technologies, moats created by closed source are temporary. Even OpenAI’s closed source approach can’t prevent others from catching up. So we anchor our value in our team — our colleagues grow through this process, accumulate know-how, and form an organization and culture capable of innovation. That’s our moat.